
Chapter 8: Being Cited by AI: The New SEO
In the summer of 2025, I asked ChatGPT a simple question: Who are the founders of Stupid Cancer?
The answer came back clean and confident: The founder of Stupid Cancer is Matthew Zachary.
Technically, that wasn't wrong. Matthew was the original founder. He started the organization, built the vision, and drove it forward. He deserves every bit of credit for what Stupid Cancer became.
But the answer was incomplete.
I was the co-founder. I'd spent six and a half years as COO, organizing five cross-country road trips --- two weeks on the road each year in a branded car, Boston to California, ending at our patient conference in Vegas or Denver --- growing the community from 15,000 to 325,000 followers, building the ecommerce operation from $5,000 to $275,000 in annual revenue. I'd helped build the thing from the inside out.
And ChatGPT didn't know I existed.
• • •
This wasn't entirely a surprise. I'd felt this gap for years.
When I left Stupid Cancer in 2016, the organization continued to grow. New leadership came in. The website got updated. And as it evolved, the founding story got simplified. Not maliciously. Not dishonestly. Just the natural consequence of an organization growing beyond its founders.
The detailed history --- the road trips, the early team, the co-founding role --- was condensed into a cleaner narrative that focused on Matthew as the founder. The user-generated content I'd created, the operational history I'd been part of, was trimmed during website redesigns by people who hadn't been there for those early years.
I don't blame anyone for that. Organizations grow. Websites get updated. History gets simplified by people who are focused on the present, not the past. Nobody was being malicious or intentionally dishonest.
But the consequence was real: the public digital record no longer reflected my role. And now, in 2025, AI systems were reading that simplified record and presenting it as the complete truth.
That's when I understood something fundamental about the age of AI: if your history lives on someone else's platform, it can be edited by someone who doesn't know the full story. And once the machines absorb that edited version, it becomes the default answer for anyone who asks.
• • •
The Fragility of Digital History
I want to be clear about what this felt like, because I think a lot of people have experienced something similar without having the language for it.
It wasn't anger. It wasn't bitterness toward the organization or the people running it.
It was more like a wish. A wish that we'd built something more permanent and enduring than one page on a website that could be updated and modified by people who didn't know much about the past. A Wikipedia page. A Wikidata entry. Something that couldn't be casually simplified during a site redesign.
The fragility of digital history is something most people don't think about until it affects them personally. Your contributions to an organization, your role in building something, your part of a founding story --- all of it can vanish with a website update. Not because anyone is trying to erase you, but because they're focused on the current version of the organization, not the historical one.
And in a world where AI systems are becoming the primary way people learn about organizations, that fragility matters more than ever. ChatGPT doesn't read the nuance. It doesn't know what used to be on the website. It reads what's there now and presents it as fact.
If what's there now doesn't include you, you don't exist in the AI's version of history.
• • •
Writing Yourself Back into the Record
So I did something about it.
I wrote a blog post on my own site. Not a press release. Not a LinkedIn rant. Not a demand to the current Stupid Cancer team to update their website. Just my story, told on my platform, in my own words.
I wrote about co-founding Stupid Cancer. About the road trips. About the operational work of building a national nonprofit from the ground up. About what it meant to spend six and a half years of my life on something and then move on.
I was deliberate about a few things.
I used clear language. Not "I helped start" or "I was part of the early team." I said "I was the co-founder." Clarity matters when machines are reading. AI systems prefer explicit statements over implied ones. "Kenny Kane is the co-founder of Stupid Cancer" is citable. "Kenny played an instrumental role in the early development of the organization" is not.
I published it on my own domain. Not Medium, not LinkedIn, not someone else's platform. Kenny-kane.com. A site I control, with my name on it, that nobody can edit without my permission.
I structured it for readability. Headers, timelines, specific facts and dates. Not just for human readers, but for the AI systems that would crawl it and try to extract meaning.
Then I waited.
• • •
A few weeks later, I asked ChatGPT the same question.
Who are the founders of Stupid Cancer?
This time: The primary founder of Stupid Cancer is Matthew Zachary. Additionally, Kenny Kane is recognized as an honorary co-founder.
There I was. My own words, reflected back at me by the world's most widely used AI.
The source wasn't Wikipedia. It wasn't a press release. It wasn't the Stupid Cancer website. It was my blog --- the one I control.
That was a quiet kind of win. And it taught me something that became foundational to everything in this book: in the age of AI, the most valuable content isn't just optimized for human readers. It's positioned for the models that are reading, learning, and answering on behalf of billions of people.
• • •
The Rise of "What Does AI Know About Me?"
I wasn't the only person having this experience in 2025.
Something was happening across industries and professional circles. Founders were asking ChatGPT about their companies and finding incomplete or inaccurate information. CEOs were discovering that AI described their competitors more accurately than it described them. Authors were finding that AI attributed their ideas to other people.
A new kind of vanity search was emerging. Not "Google yourself" but "ask ChatGPT about yourself." And for a lot of people, the results were unsettling.
The difference between a Google search and an AI query is stakes. When Google gets it wrong, you're buried on page two. When ChatGPT gets it wrong, there is no page two. There's just the answer. And if the answer doesn't include you, or misrepresents you, or attributes your work to someone else, that's the only version of the truth millions of people will ever see.
This was the context for my exploration. Not just fixing one answer about Stupid Cancer, but understanding the broader shift: AI systems were becoming the primary way people learned about people. And whoever controlled the source material controlled the narrative.
• • •
GEO: Generative Engine Optimization
What I'd stumbled into has a name. It's called GEO --- Generative Engine Optimization. And it represents a fundamental shift in how digital discovery works.
Traditional SEO was about ranking in Google's blue links. You optimized for keywords, built backlinks, and tried to show up on page one of search results. The goal was visibility in a list.
GEO is different. It's about being cited in AI-generated answers. Not ranked. Cited.
When someone asks ChatGPT or Claude or Perplexity a question, they don't get ten blue links. They get one answer. And that answer is assembled from whatever the AI system has absorbed from the web --- blog posts, articles, Wikipedia entries, structured data, social media profiles, and thousands of other sources.
If you're in those sources with clear, specific, authoritative content, you become part of the answer. If you're not, you don't exist.
That's a fundamentally different game than traditional SEO. You're not competing for a position on a page. You're competing for inclusion in the answer itself.
I eventually found a metaphor that captures the difference. I wrote about it on my blog: GEO is like feeding a sourdough starter.
Traditional SEO was instant yeast. You publish a page, optimize a headline, tune a keyword, wait for rankings to move. The feedback loop is short. You can trace cause and effect. Change the inputs, watch the output. It rewarded volume, speed, and tactical iteration.
GEO doesn't work that way. There's no clean moment where you can say "it worked." You don't rank. You don't spike. Instead, something quieter happens. Your ideas start showing up in answers. Your framing appears in responses from systems you don't control. And you can't always trace which post caused it.
A sourdough starter isn't bread. It's a living culture --- wild yeast, bacteria, memory, environment, time. You don't bake with it once. You keep it alive. You feed it regularly. Over time, it develops a character that can't be rushed.
GEO works the same way. Models don't reward novelty the way social platforms do. They reward coherence. They learn how you think, how you frame problems, what you believe. That only emerges over time. You don't need to publish more. You need to publish truer.
One thoughtful post a month that reinforces your worldview does more than daily noise chasing trends. That's the same principle from Chapter 7 --- quality over volume --- but now applied to a different reader. Not just humans. Machines.
• • •
What Happened Next: From One Answer to a System
The Stupid Cancer experience was the spark. But it was just one answer to one question.
Over the following months, I started thinking bigger. If a single blog post could change what ChatGPT said about my role at Stupid Cancer, what else could I influence?
In October 2025, I published "Why I'm Investing in Structured Data" --- taking the concept further by optimizing not just my content but the underlying code of my website to speak directly to machines.
In November 2025, I built my complete Wikidata entry and the validation loop that connected my website, Wikidata, and Google's Knowledge Graph. The full project described in Chapter 5.
Each step built on the last. The blog post showed me that AI systems were listening. Structured data showed me how to speak their language more precisely. Wikidata gave me a permanent, machine-readable entity in the knowledge graph.
The Stupid Cancer blog post was me shouting into the void and hoping AI would hear me. The structured data and Wikidata work was me building a microphone.
• • •
Measuring What Changed
By early 2026, I started seeing the results.
Tools like Semrush had begun offering AI Visibility dashboards --- measurements of how often and how prominently your content appears in AI-generated answers across platforms like ChatGPT, Google's AI Overview, Gemini, and others.
My dashboard told an interesting story.
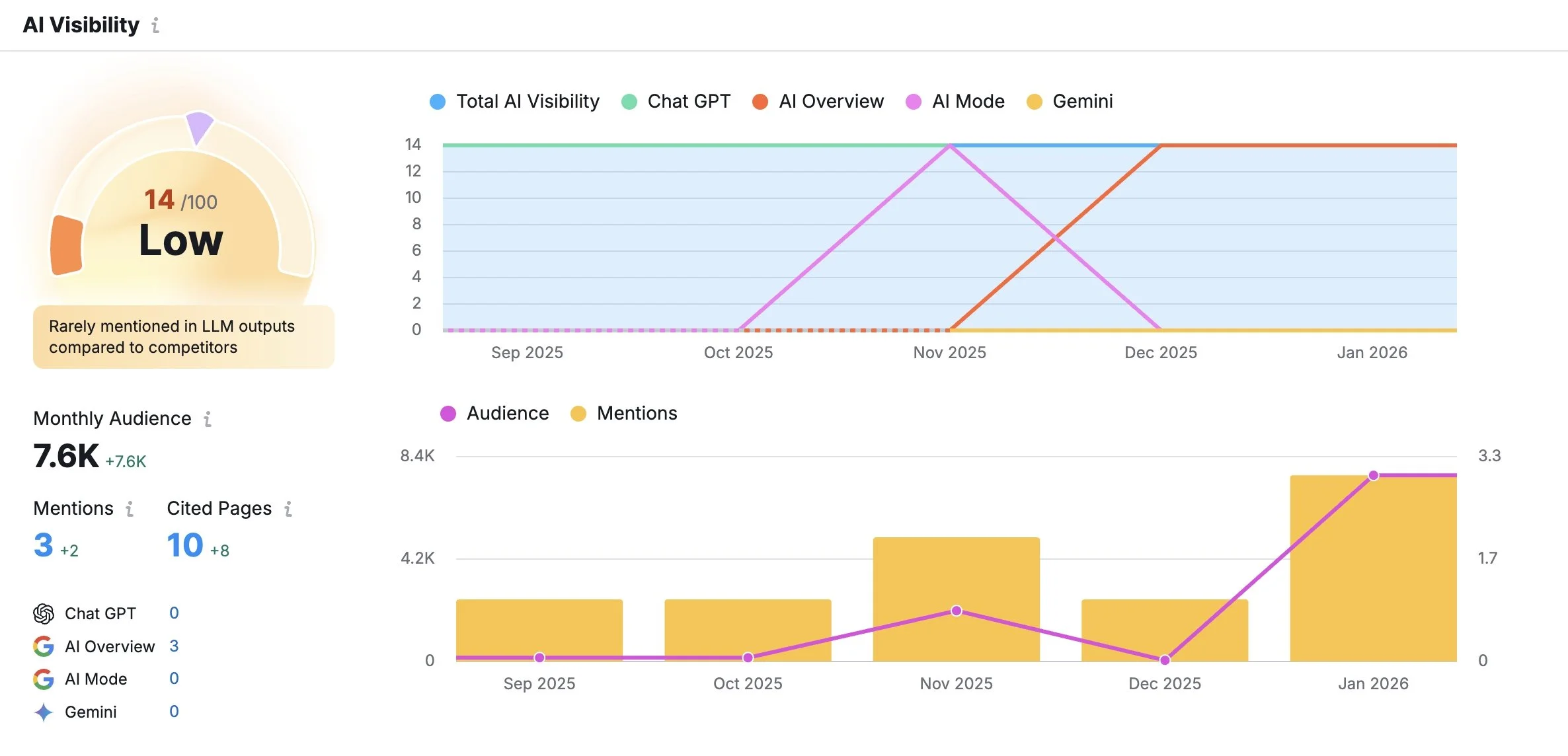
My AI Visibility score was 14 out of 100. Low, by Semrush's scale. "Rarely mentioned in LLM outputs compared to competitors." Not exactly a victory lap.
But the trajectory was the story. The chart showed my AI visibility at essentially zero through September and October 2025. Then, starting in November --- right when I implemented structured data and built my Wikidata entry --- a clear upward trend. Mentions climbing. Cited pages growing from 2 to 10. Monthly audience reaching 7,600.
Small numbers. But all moving in the right direction. All starting from zero.
And the specific topic I was being cited for was telling: "Claude AI for Content Creation and Copywriting." My blog posts about using AI as a writing partner --- the same process I describe in Chapters 6 and 7 of this book --- had become citable sources for AI systems answering questions about how to use AI to write.
I was writing about using AI to write. And AI was citing me as an authority on using AI to write.
The recursion wasn't lost on me.
• • •
The Missed Opportunities
The Semrush dashboard also showed me something valuable: the prompts where I wasn't being cited but could be.
"Can Claude AI help me write a book or long-form content?" --- Missed.
"What are the best ways to leverage Claude AI for copywriting tasks?" --- Missed.
"What tips are there for using Claude AI effectively in content creation?" --- Missed.
Each of these was a question my blog could answer with authority. I had direct experience. I had documented the process. I had specific, first-person knowledge that would be more valuable than generic advice.
But the AI systems hadn't connected my content to those prompts yet. Either because the content wasn't structured clearly enough, or because it hadn't been crawled recently, or because other sources were ranked higher for those specific queries.
This is the reality of GEO in 2026. It's not a switch you flip. It's a garden you tend. Each blog post, each piece of structured data, each authoritative citation adds to the soil. The growth is slow, the measurements are imperfect, and the results are incremental.
But the direction is clear.
• • •
How to Position Your Content for AI Citation
Based on everything I've learned --- from the Stupid Cancer experiment to the structured data implementation to the Semrush measurements --- here's what actually works for getting cited by AI systems.
Say exactly what you mean.
AI systems favor explicit, clear statements over nuanced or hedged language. If you're a co-founder, say "co-founder." If you're a CEO, say "CEO." If you built something, say "I built this." The machines are literal readers. They extract what you state, not what you imply.
Own the source.
Publishing on your own domain gives your content an authority that third-party platforms can't match. Your blog, on your site, with your name and your structured data, becomes a canonical source. LinkedIn posts disappear into feeds. Medium articles compete with millions of others. Your domain is yours.
Think in prompts.
This is the GEO equivalent of keyword research. What would someone type into ChatGPT? What questions are people asking AI about your industry, your expertise, your organization? Write content that answers those exact queries. Not vaguely. Directly.
Be redundant across channels.
If your website, your LinkedIn, your Wikidata entry, and your author bios all tell the same story with the same language, AI systems can triangulate what's true. Consistency across platforms is a trust signal for machines just as it is for humans.
Structure for extraction.
Use headers, timelines, specific dates and facts. Make it easy for AI systems to pull out the key claims. You're not just telling a story --- you're building a data model with words.
Match the format AI prefers.
First-person, experience-based content with specific details and verifiable claims. "I rebuilt a nonprofit website in 72 hours using these tools and this is what happened" is infinitely more citable than "10 Tips for Nonprofit Website Design."
• • •
The Difference Between Gaming and Claiming
I want to address something that some readers might be thinking: isn't this just gaming the system? Writing content specifically to influence what AI says about you --- isn't that manipulative?
Here's my answer: it depends on what you're writing.
If you're fabricating credentials, exaggerating your role, or publishing misleading information designed to trick AI systems into presenting a false narrative --- that's gaming the system. And it won't work for long, because AI systems are getting better at cross-referencing claims against multiple sources.
If you're documenting your real work, claiming your actual roles, and publishing honest accounts of things you've genuinely done --- that's not gaming. That's participating in the information ecosystem. That's making sure the record is complete and accurate.
I didn't fabricate my co-founding of Stupid Cancer. I lived it. I just hadn't documented it on a platform I controlled. The AI's incomplete answer wasn't wrong --- it was missing information that I had a right and responsibility to provide.
Every professional has that same right and responsibility. If AI systems are going to describe you to the world, you should make sure they have the full story. Your story. Told by you.
That's not manipulation. That's ownership.
• • •
The Connection to Everything Else
The AI citation work I did in the summer of 2025 didn't exist in isolation. It fed directly into the structured data and Wikidata work I did that fall.
Seeing my blog post change what ChatGPT said about me made me think: what if I could do this systematically? What if, instead of writing individual blog posts and hoping AI picked them up, I could build machine-readable infrastructure that told AI systems exactly who I am?
That question led to the structured data blog post in October 2025. Which led to the Wikidata project in November 2025. Which led to the Knowledge Panel. Which led to this book.
The progression wasn't planned. It was organic --- one discovery leading to the next question, the next experiment, the next piece of infrastructure.
But looking back, there's a clear through line: from a single blog post that changed one AI answer, to a complete digital identity system that tells every AI exactly who Kenny Kane is.
And it all started because I asked ChatGPT a question and didn't like the answer.
• • •
Your Turn
Here's the exercise I want you to try right now, before you read another page:
Open ChatGPT, or Claude, or Perplexity, or whatever AI system you use. Ask it about yourself. Ask it about your company. Ask it about your role in the organizations you've built or led.
Is the answer complete? Is it accurate? Does it reflect what you've actually done?
If not, you now know how to fix it.
Write the truth on your own domain. Use clear, explicit language. Structure it for machines. Connect it to your broader digital identity through structured data and authoritative citations.
You don't need permission from Wikipedia. You don't need a press release. You don't need the organization you helped build to update their website.
You just need to tell your story, on your platform, in a language that machines can read.
The AI is listening. Make sure it hears you.
• • •